
NVIDIA NeMo Framework

Spesifikaasjes
- Produkt Namme: NVIDIA NeMo Framework
- Beynfloede platfoarms: Windows, Linux, macOS
- Beynfloede ferzjes: Alle ferzjes foarôfgeand oan 24
- Feiligens kwetsberens: CVE-2025-23360
- Basisscore foar risiko-beoardieling: 7.1 (CVSS v3.1)
Produkt Usage Ynstruksjes
Ynstallaasje fan befeiligingsupdate:
Om jo systeem te beskermjen, folgje dizze stappen:
- Download de lêste release fan 'e NeMo-Framework-Launcher Releases side op GitHub.
- Gean nei NVIDIA Product Security foar fierdere ynformaasje.
Feiligens Update Details:
De befeiligingsupdate behannelet in kwetsberens yn it NVIDIA NeMo Framework dat kin liede ta koade-útfiering en gegevens tampering.
Software Upgrade:
As jo in eardere branch-release brûke, is it oan te rieden om te upgrade nei de lêste branch-release om it feiligensprobleem oan te pakken.
Oerview
NVIDIA NeMo Framework is in skalberber en cloud-native generatyf AI-ramt boud foar ûndersikers en ûntwikkelders dy't wurkje oan Grutte taalmodellen, Multimodaal, en Speech AI (bgl Automatyske spraakherkenning en Tekst-nei-spraak). It stelt brûkers yn steat om effisjint nije generative AI-modellen oan te meitsjen, oan te passen en yn te setten troch besteande koade en pre-trained modelkontrôlepunten te benutten.
Setup Ynstruksjes: Ynstallearje NeMo Framework
NeMo Framework biedt end-to-end stipe foar it ûntwikkeljen fan Large Language Models (LLM's) en Multimodal Models (MMs). It biedt de fleksibiliteit om te brûken op it terrein, yn in datasintrum, of mei jo foarkar wolkprovider. It stipet ek útfiering op SLURM of Kubernetes ynskeakele omjouwings.

Data Curation
NeMo-kurator [1] is in Python-bibleteek dy't in suite fan modules omfettet foar data mining en syntetyske datageneraasje. Se binne skalberber en optimalisearre foar GPU's, wêrtroch't se ideaal binne foar it kurearjen fan natuerlike taalgegevens om LLM's te trenen of te fine. Mei NeMo Curator kinne jo tekst fan hege kwaliteit effisjint ekstrahearje út wiidweidige rau web gegevens boarnen.
Training en maatwurk
NeMo Framework jout ark foar effisjinte training en maatwurk fan LLMs en Multimodale modellen. It omfettet standertkonfiguraasjes foar opset fan komputerkluster, it downloaden fan gegevens en modelhyperparameters, dy't kinne wurde oanpast om te trenen op nije datasets en modellen. Neist pre-training stipet NeMo sawol Supervised Fine-Tuning (SFT) en Parameter Efficient Fine-Tuning (PEFT) techniken lykas LoRA, Ptuning, en mear.
Twa opsjes binne beskikber om training yn NeMo te starten - mei de NeMo 2.0 API-ynterface of mei NeMo Run.
- Mei NeMo Run (oanrikkemandearre): NeMo Run biedt in ynterface om konfiguraasje, útfiering en behear fan eksperiminten yn ferskate komputeromjouwings te streamlynjen. Dit omfettet it lansearjen fan banen op jo wurkstasjon lokaal as op grutte klusters - sawol SLURM ynskeakele as Kubernetes yn in wolkomjouwing.
- Pre-training & PEFT Quickstart mei NeMo Run
- Mei de NeMo 2.0 API: Dizze metoade wurket goed mei in ienfâldige opset wêrby't lytse modellen, of as jo ynteressearre binne yn it skriuwen fan jo eigen oanpaste dataloader, training loops, of feroarje model lagen. It jout jo mear fleksibiliteit en kontrôle oer konfiguraasjes, en makket it maklik te wreidzjen en oanpasse konfiguraasjes programmatysk.
-
Trayning Quickstart mei NeMo 2.0 API
-
Migrearje fan NeMo 1.0 nei NeMo 2.0 API
-
Alignment
- NeMo-Aligner [1] is in scalable toolkit foar effisjinte model alignment. De toolkit hat stipe foar state-of-the-art model alignment algoritmen lykas SteerLM, DPO, Reinforcement Learning from Human Feedback (RLHF), en folle mear. Dizze algoritmen kinne brûkers taalmodellen ôfstimme om feiliger, harmlesser en behelpsumer te wêzen.
- Alle NeMo-Aligner-kontrôlepunten binne cross-kompatibel mei it NeMo-ekosysteem, wêrtroch't fierdere oanpassing en ynfeksje ynset wurde kinne.
Stap-foar-stap workflow fan alle trije fazen fan RLHF op in lyts GPT-2B-model:
- SFT training
- Beleanning model training
- PPO training
Derneist demonstrearje wy stipe foar ferskate oare nije ôfstimmingsmetoaden:
- DPO: in lichtgewicht ôfstimmingsalgoritme yn ferliking mei RLHF mei in ienfâldiger ferliesfunksje.
- Self-Play Fine-Tuning (SPIN)
- SteerLM: in technyk basearre op conditioned-SFT, mei steerable útfier.
Besjoch de dokumintaasje foar mear ynformaasje: Alignment Documentation
Multimodale modellen
- NeMo Framework leveret optimisearre software om moderne multimodale modellen op te trenen en yn te setten oer ferskate kategoryen: Multimodale taalmodellen, fyzje-taalfunderingen, tekst-nei-ôfbyldingsmodellen, en fierder 2D-generaasje mei help fan Neural Radiance Fields (NeRF).
- Elke kategory is ûntworpen om te foldwaan oan spesifike behoeften en foarútgong op it fjild, troch gebrûk te meitsjen fan moderne modellen om in breed oanbod fan gegevenstypen te behanneljen, ynklusyf tekst, ôfbyldings en 3D-modellen.
Noat
Wy migrearje stipe foar multimodale modellen fan NeMo 1.0 nei NeMo 2.0. As jo dit domein yn 'e tuskentiid wolle ferkenne, ferwize dan nei de dokumintaasje foar de NeMo 24.07 (foarige) release.
Ynset en konklúzje
NeMo Framework biedt ferskate paden foar LLM-konklúzje, catering foar ferskate ynsetsenario's en prestaasjesbehoeften.
Ynsette mei NVIDIA NIM
- NeMo Framework yntegreart naadloos mei ark foar ynset fan modellen op bedriuwsnivo fia NVIDIA NIM. Dizze yntegraasje wurdt oandreaun troch NVIDIA TensorRT-LLM, en soarget foar optimalisearre en skalberbere konklúzje.
- Foar mear ynformaasje oer NIM, besykje de NVIDIA website.
Ynsette mei TensorRT-LLM of vLLM
- NeMo Framework biedt skripts en API's om modellen te eksportearjen nei twa inference-optimisearre biblioteken, TensorRT-LLM en vLLM, en om it eksportearre model yn te setten mei de NVIDIA Triton Inference Server.
- Foar senario's dy't optimalisearre prestaasjes fereaskje, kinne NeMo-modellen TensorRT-LLM brûke, in spesjalisearre bibleteek foar it fersnellen en optimalisearjen fan LLM-ynferinsje op NVIDIA GPU's. Dit proses giet it om it konvertearjen fan NeMo-modellen yn in formaat dat kompatibel is mei TensorRT-LLM mei de nemo.export-module.
- LLM-ynset oerview
- Ynsette NeMo Large Language Models mei NIM
- Ynsette NeMo Large Language Models mei TensorRT-LLM
- Ynsette NeMo Large Language Models mei vLLM
Stipe modellen
Grutte taalmodellen
| Grutte taalmodellen | Pretraining & SFT | PEFT | Alignment | FP8 Training Convergence | TRT/TRTLLM | Konvertearje nei en fan knuffelgesicht | Evaluaasje |
|---|---|---|---|---|---|---|---|
| Lama3 8B/70B, Lama3.1 405B | Ja | Ja | x | Ja (foar in part ferifiearre) | Ja | Beide | Ja |
| Mixtral 8x7B / 8x22B | Ja | Ja | x | Ja (net ferifiearre) | Ja | Beide | Ja |
| Nemotron 3 8B | Ja | x | x | Ja (net ferifiearre) | x | Beide | Ja |
| Nemotron 4 340B | Ja | x | x | Ja (net ferifiearre) | x | Beide | Ja |
| Baichuan2 7B | Ja | Ja | x | Ja (net ferifiearre) | x | Beide | Ja |
| ChatGLM3 6B | Ja | Ja | x | Ja (net ferifiearre) | x | Beide | Ja |
| Gemma 2B/7B | Ja | Ja | x | Ja (net ferifiearre) | Ja | Beide | Ja |
| Gemma2 2B/9B/27B | Ja | Ja | x | Ja (net ferifiearre) | x | Beide | Ja |
| Mamba2 130M/370M/780M/1.3B/2.7B/8B/ Hybrid-8B | Ja | Ja | x | Ja (net ferifiearre) | x | x | Ja |
| Phi3 mini 4k | x | Ja | x | Ja (net ferifiearre) | x | x | x |
| Qwen2 0.5B/1.5B/7B/72B | Ja | Ja | x | Ja (net ferifiearre) | Ja | Beide | Ja |
| StarCoder 15B | Ja | Ja | x | Ja (net ferifiearre) | Ja | Beide | Ja |
| StarCoder2 3B/7B/15B | Ja | Ja | x | Ja (net ferifiearre) | Ja | Beide | Ja |
| BERT 110M/340M | Ja | Ja | x | Ja (net ferifiearre) | x | Beide | x |
| T5 220M/3B/11B | Ja | Ja | x | x | x | x | x |
Vision Taal Models
| Vision Taal Models | Pretraining & SFT | PEFT | Alignment | FP8 Training Convergence | TRT/TRTLLM | Konvertearje nei en fan knuffelgesicht | Evaluaasje |
|---|---|---|---|---|---|---|---|
| NeVA (LLaVA 1.5) | Ja | Ja | x | Ja (net ferifiearre) | x | Fan | x |
| Llama 3.2 Vision 11B/90B | Ja | Ja | x | Ja (net ferifiearre) | x | Fan | x |
| LLaVA Folgjende (LLaVA 1.6) | Ja | Ja | x | Ja (net ferifiearre) | x | Fan | x |
Ynbêde modellen
| Taalmodellen ynbêde | Pretraining & SFT | PEFT | Alignment | FP8 Training Convergence | TRT/TRTLLM | Konvertearje nei en fan knuffelgesicht | Evaluaasje |
|---|---|---|---|---|---|---|---|
| SBERT 340M | Ja | x | x | Ja (net ferifiearre) | x | Beide | x |
| Lama 3.2 Ynbêding 1B | Ja | x | x | Ja (net ferifiearre) | x | Beide | x |
World Foundation Models
| World Foundation Models | Post-oplieding | Accelerated Inference |
|---|---|---|
| Cosmos-1.0-Diffusion-Text2World-7B | Ja | Ja |
| Cosmos-1.0-Diffusion-Text2World-14B | Ja | Ja |
| Cosmos-1.0-Diffusion-Video2World-7B | Meikoarten | Meikoarten |
| Cosmos-1.0-Diffusion-Video2World-14B | Meikoarten | Meikoarten |
| Cosmos-1.0-Autoregressive-4B | Ja | Ja |
| Cosmos-1.0-Autoregressive-Video2World-5B | Meikoarten | Meikoarten |
| Cosmos-1.0-Autoregressive-12B | Ja | Ja |
| Cosmos-1.0-Autoregressive-Video2World-13B | Meikoarten | Meikoarten |
Noat
NeMo stipet ek foartraining foar sawol diffusion as autoregressive arsjitektuer text2world stifting modellen.
Speech AI
It ûntwikkeljen fan konversaasje-AI-modellen is in kompleks proses dat it definiearjen, konstruearjen en oplieden fan modellen binnen bepaalde domeinen omfettet. Dit proses fereasket typysk ferskate iteraasjes om in heech nivo fan krektens te berikken. It giet faak om meardere iteraasjes om hege krektens te berikken, fine-tuning op ferskate taken en domeinspesifike gegevens, garandearjen fan trainingsprestaasjes, en it tarieden fan modellen foar ynfeksje-ynset.
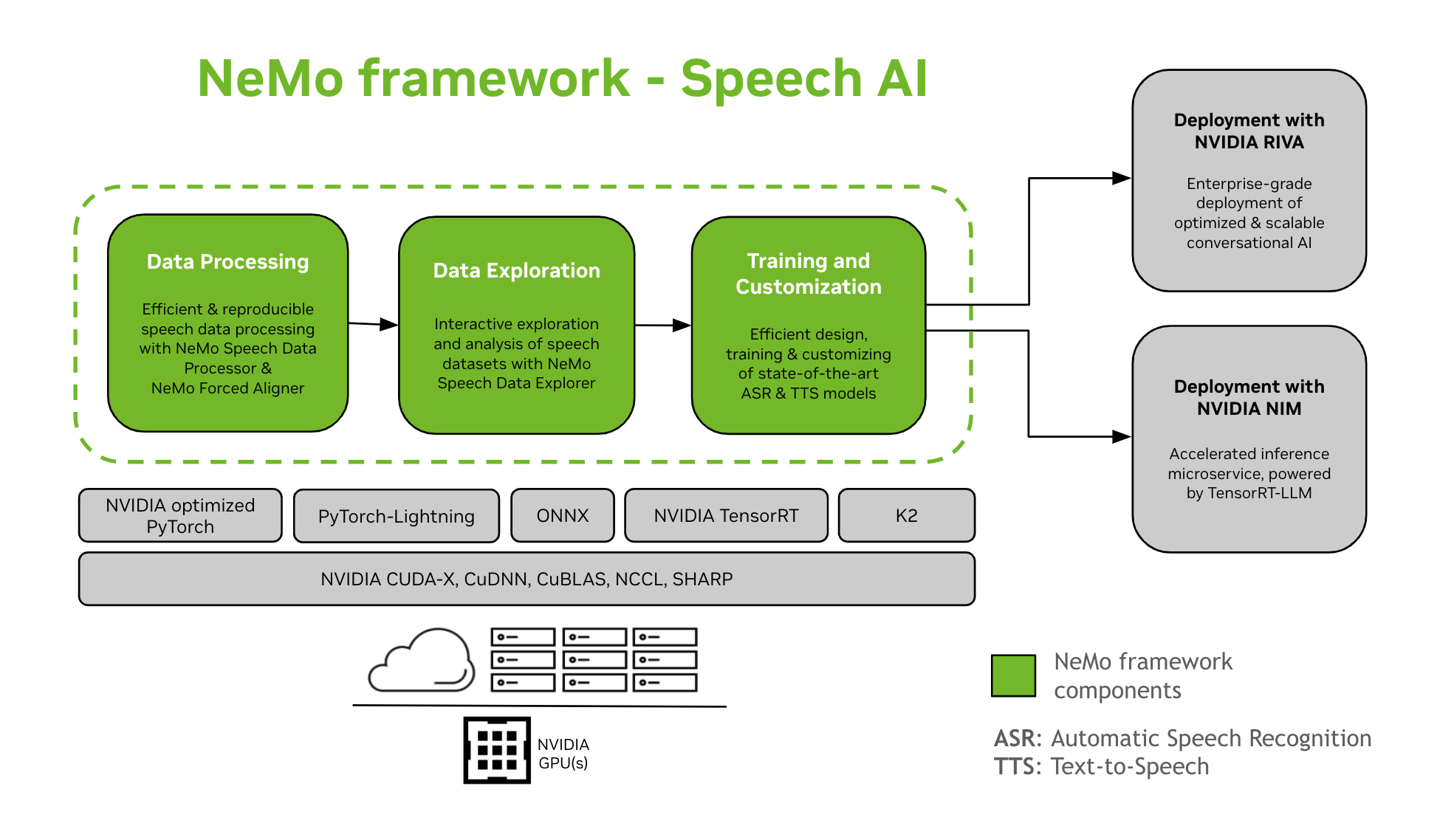
NeMo Framework biedt stipe foar de training en oanpassing fan Speech AI-modellen. Dit omfettet taken lykas Automatic Speech Recognition (ASR) en Text-To-Speech (TTS) synteze. It biedt in soepele oergong nei produksje-ynset op bedriuwsnivo mei NVIDIA Riva. Om ûntwikkelders en ûndersikers te helpen, omfettet NeMo Framework state-of-the-art pre-trained checkpoints, ark foar reprodusearbere spraakgegevensferwurking, en funksjes foar ynteraktive ferkenning en analyze fan spraakdatasets. De komponinten fan it NeMo Framework for Speech AI binne as folget:
Training en maatwurk
NeMo Framework befettet alles wat nedich is om spraakmodellen te trainen en oan te passen (ASR, Speech Klassifikaasje, Speaker Erkenning, Speaker Diarization, en TTS) op in reprodusearjende manier.
SOTA Pre-trained modellen
- NeMo Framework jout state-of-the-art resepten en pre-trained checkpoints fan ferskate ASR en TTS modellen, en ek ynstruksjes oer hoe't jo se laden.
- Speech Tools
- NeMo Framework biedt in set ark nuttich foar it ûntwikkeljen fan ASR- en TTS-modellen, ynklusyf:
- NeMo Forced Aligner (NFA) foar it generearjen fan token-, wurd- en segmentnivo-timestamps fan spraak yn audio mei NeMo's CTC-basearre modellen foar automatyske spraakherkenning.
- Speech Data Processor (SDP), in ark foar it ferienfâldigjen fan spraakgegevensferwurking. It lit jo gegevensferwurkingsoperaasjes fertsjintwurdigje yn in konfiguraasje file, minimearje boilerplate koade en tastean reproducibility en shareability.
- Speech Data Explorer (SDE), in Dash-basearre web applikaasje foar ynteraktive ferkenning en analyze fan spraak datasets.
- Tool foar oanmeitsjen fan datasets dy't funksjonaliteit leveret om lange audio út te rjochtsjen files mei de korrespondearjende transkripsjes en split se yn koartere fragminten dy't geskikt binne foar Automatic Speech Recognition (ASR) model training.
- Ferliking Tool foar ASR-modellen om foarsizzings fan ferskate ASR-modellen te fergelykjen op wurdkrektens en uteringsnivo.
- ASR Evaluator foar it evaluearjen fan de prestaasjes fan ASR-modellen en oare funksjes lykas Voice Activity Detection.
- Tekstnormalisaasje-ark foar it konvertearjen fan tekst fan 'e skreaune foarm nei de sprutsen foarm en oarsom (bgl. "31st" vs "thirty first").
- Paad nei ynset
- NeMo-modellen dy't binne oplaat of oanpast mei it NeMo-framework kinne wurde optimalisearre en ynset mei NVIDIA Riva. Riva leveret konteners en Helm-kaarten spesifyk ûntworpen om de stappen te automatisearjen foar ynset fan drukknoppen.
Oare Resources
- NeMo: De wichtichste repository foar it NeMo Framework
- NeMo–Run: In ark om jo masine-lear-eksperiminten te konfigurearjen, te starten en te behearjen.
- NeMo-Aligner: Scalable toolkit foar effisjinte model ôfstimming
- NeMo-Curator: Scalable data pre-ferwurking en curation toolkit foar LLMs
Gean mei de NeMo-mienskip, stel fragen, krije stipe, of rapportearje bugs.
- NeMo Diskusjes
- NeMo Issues
Programmeertalen en kaders
- Python: De haadynterface om NeMo Framework te brûken
- Pytorch: NeMo Framework is boud boppe op PyTorch
Lisinsjes
- NeMo Github repo is lisinsje ûnder de Apache 2.0 lisinsje
- NeMo Framework is lisinsje ûnder de NVIDIA AI PRODUCT OVEREENKOMST. Troch de kontener te lûken en te brûken, akseptearje jo de betingsten fan dizze lisinsje.
- De NeMo Framework-container befettet Llama-materialen regele troch de Meta Llama3 Community License Agreement.
Fuotnoaten
Op it stuit is NeMo Curator en NeMo Aligner-stipe foar Multimodale modellen in wurk oan 'e gong en sil heul gau beskikber wêze.
FAQ
F: Hoe kin ik kontrolearje oft myn systeem wurdt beynfloede troch de kwetsberens?
A: Jo kinne kontrolearje as jo systeem beynfloede is troch de ferzje fan it ynstalleare NVIDIA NeMo Framework te kontrolearjen. As it ûnder ferzje 24 is, kin jo systeem kwetsber wêze.
F: Wa hat it befeiligingsprobleem CVE-2025-23360 rapporteare?
A: It feiligensprobleem waard rapportearre troch Or Peles - JFrog Security. NVIDIA erkent har bydrage.
F: Hoe kin ik takomstige befeiligingsbulletin-notifikaasjes ûntfange?
A: Besykje de NVIDIA Product Security-side om te abonnearjen op notifikaasjes foar befeiligingsbulletin en op 'e hichte te bliuwen oer produktfeiligensupdates.
Dokuminten / Resources
 | NeMo Framework |
Referinsjes
- User Manualmanual.tools